Belief-Grounded Networks for Accelerated Robot Learning under Partial Observability
Abstract
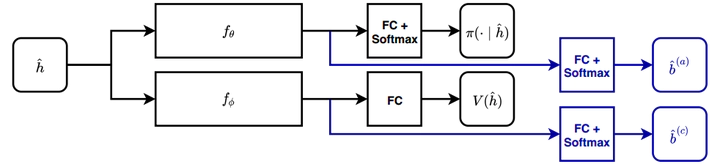
Many important robotics problems are partially observable where a single visual or force-feedback measurement is insufficient to reconstruct the state. Standard approaches involve learning a policy over beliefs or observation-action histories. However, both of these have drawbacks; it is expensive to track the belief online, and it is hard to learn policies directly over histories. We propose a method for policy learning under partial observability called the Belief-Grounded Network (BGN) in which an auxiliary belief-reconstruction loss incentivizes a neural network to concisely summarize its input history. Since the resulting policy is a function of the history rather than the belief, it can be executed easily at runtime. We compare BGN against several baselines on classic benchmark tasks as well as three novel robotic force-feedback tasks. BGN outperforms all other tested methods and its learned policies work well when transferred onto a physical robot.